【Python 爬虫初级教程 02】爬取百度翻译查询英文单词
温馨提醒:请勿滥用爬虫!
材料准备
部分准备工作已省略,参见 【Python 爬虫初级教程】手把手教你爬取12306网站列车车次信息 。
寻找文件数据
访问 百度翻译主页,按下 F12,清空网络日志,点击 “Fetch/XHR”。
在输入框尝试输入 “s”,得到下图数据: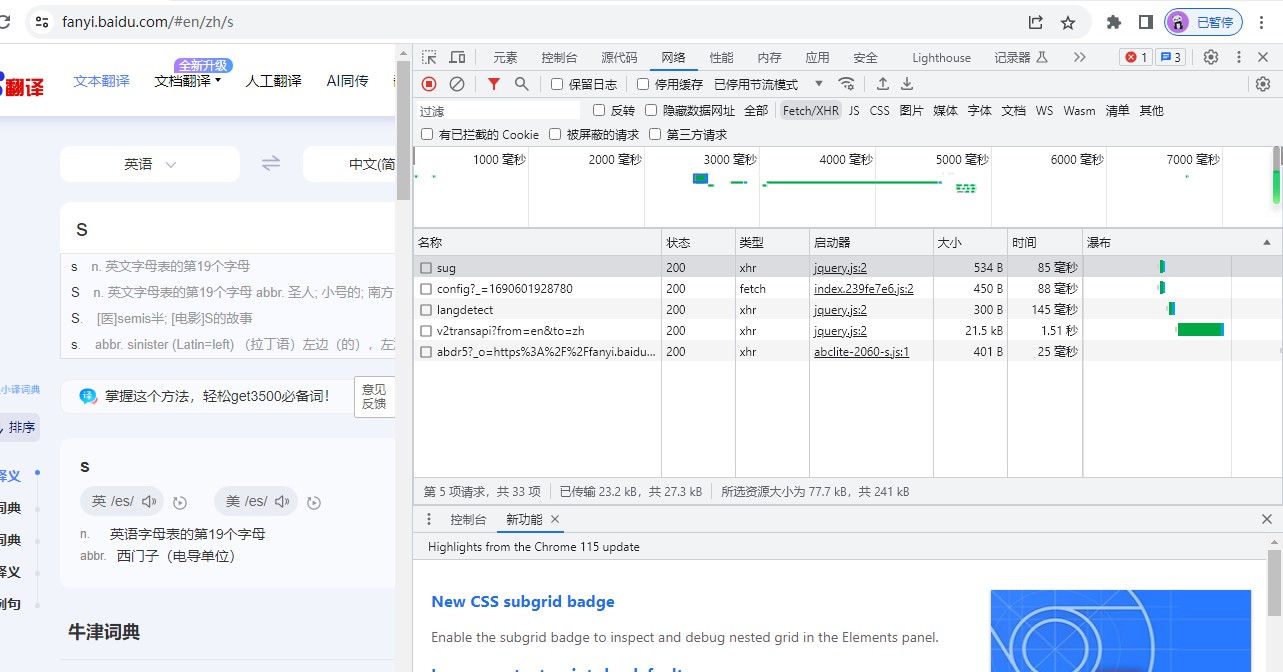
逐一查看数据内容,可以发现,在 https://fanyi.baidu.com/sug 中包含简明的翻译信息。比对网页内容,信息位于搜索联想区域。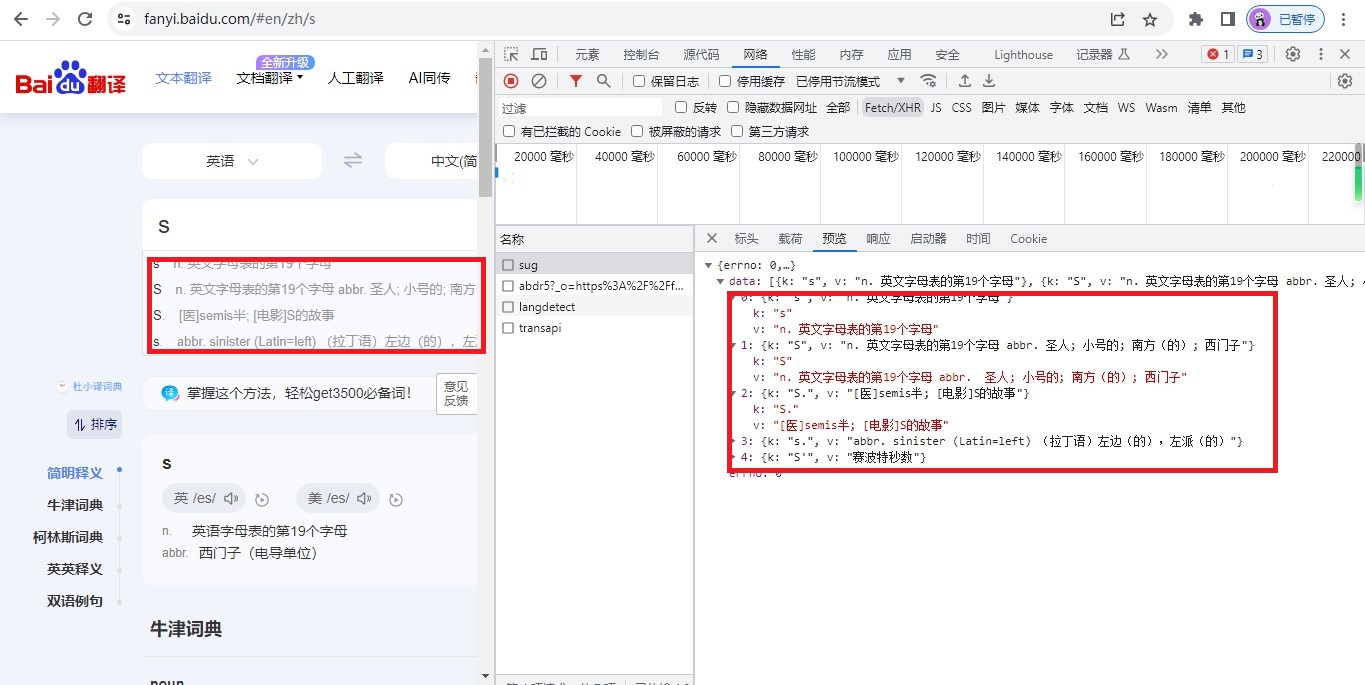
数据这次请求的方式与上次不同,爬取 12306 是用的 GET 方法,直接可以拿到数据。但百度翻译的请求链接使用 POST,需要传参给服务器等其响应。具体 GET 与 POST 的区别可见 GET 和 POST 的区别? | 知乎 。
点击 载荷,表单数据即需要传参为 kw,值为需搜索的单词。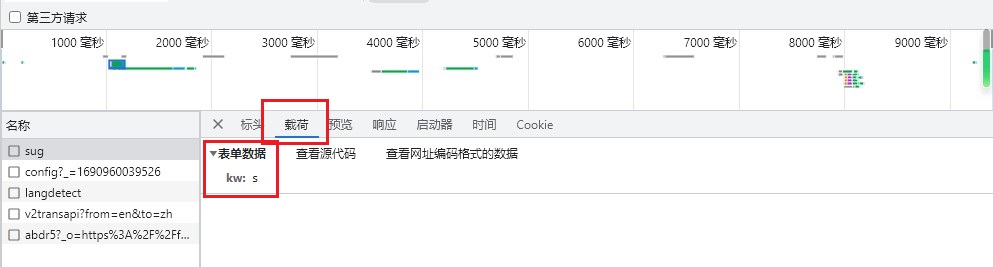
点击 预览,服务器返回参数为 json 。
在 py 中,可以使用以下代码发送 POST 请求:
1 | import requests |
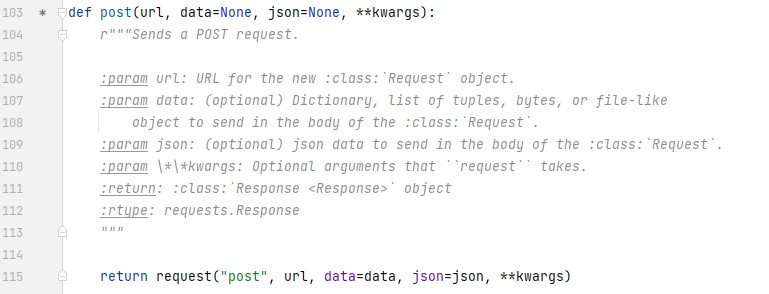
url 参数为请求链接,data 为需传参内容,字典类型。
代码部分
根据上面的分析,请求链接得到数据:
1 | import requests |
接下来进行数据处理:
1 | lst = text['data'] |
【Python 爬虫初级教程 02】爬取百度翻译查询英文单词

