这是我的第一篇 Python 爬虫文章!喜欢的话请多多支持吧!
温馨提醒:爬虫技术的出现是人类对互联网 探索的一大进步。本文仅用于学习、技术交流,运用爬虫等手段攻击他人服务器和网站的行为可能触犯相关法律法规。如出现以上情况,本站概不负责!
准备工作
顺利阅读本文的先决条件
- 你身边有一台正在工作的电脑,which 已安装 Python 软件并完成环境搭建,还能成功连上互联网。
- 你熟悉 Python 语言初级语法(至少需要了解模块的调用和函数的定义,对 Python 中的“类”和“对象”有一定认识)。
- 一双善于发现的眼睛,一个善于提出疑惑的大脑,一双能敲打键盘的手。
材料准备
环境介绍:
- 系统:Windows 10 Version 22H2
- Python 版本:v3.10.9
- 浏览器:Google Chrome 版本 111.0.5563.147 正式版本 64 位 (其他浏览器操作方法相似)
需要用到的网站:
本文的示例参数:
- 列车始发地:北京
- 列车目的地:杭州
- 列车发出时间:2023-06-01
- 票种类型:成人票
安装 Python 第三方模块
你需要安装的有:
- prettytable
- docopt
- requests
- colorama
对应需要输入至终端的代码:
- pip install prettytable
- pip install docopt
- pip install requests
- pip install colorama
反复重试仍报错,请及时于评论区联系我!如果还有疑惑,推荐查阅 Python pip 安装与使用 | 菜鸟教程 和 73. python第三方库安装教程(超详细) | 知乎 。你还可以在评论区与我讨论!
寻找文件数据
访问 12306 官网,按下高贵的 F12 键(笔记本电脑同时按下 Fn + F12 键),你就会看到下图页面:
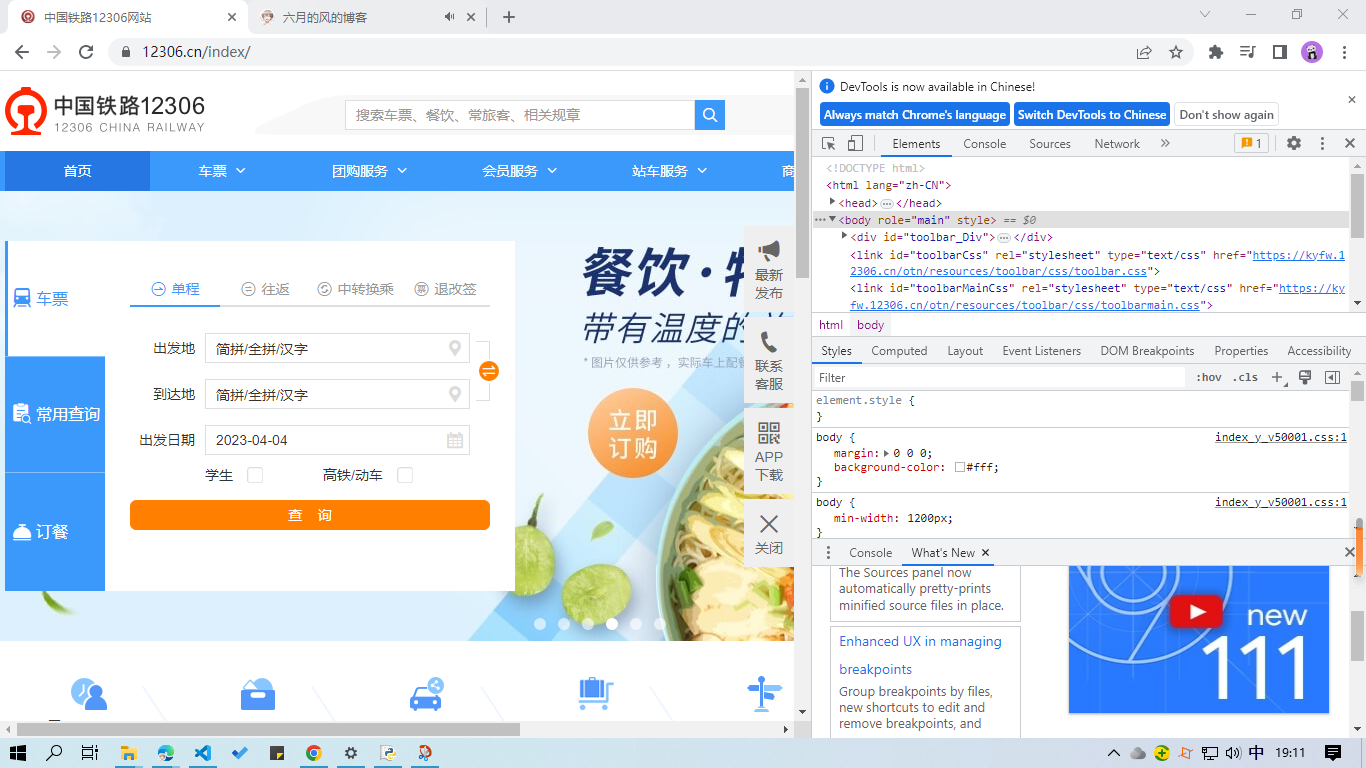
如果你的英语足够优秀,不进行语言设置也无伤大雅;但如果你是像我这样的英语渣渣,那么赶快点击 "Always match Chrome's language"(也可以在 DevTools 的设置中更改语言)。
按照下图设置,点击 "网络" ,点击 "刷新",你会看到一连串网页加载的资源文件。
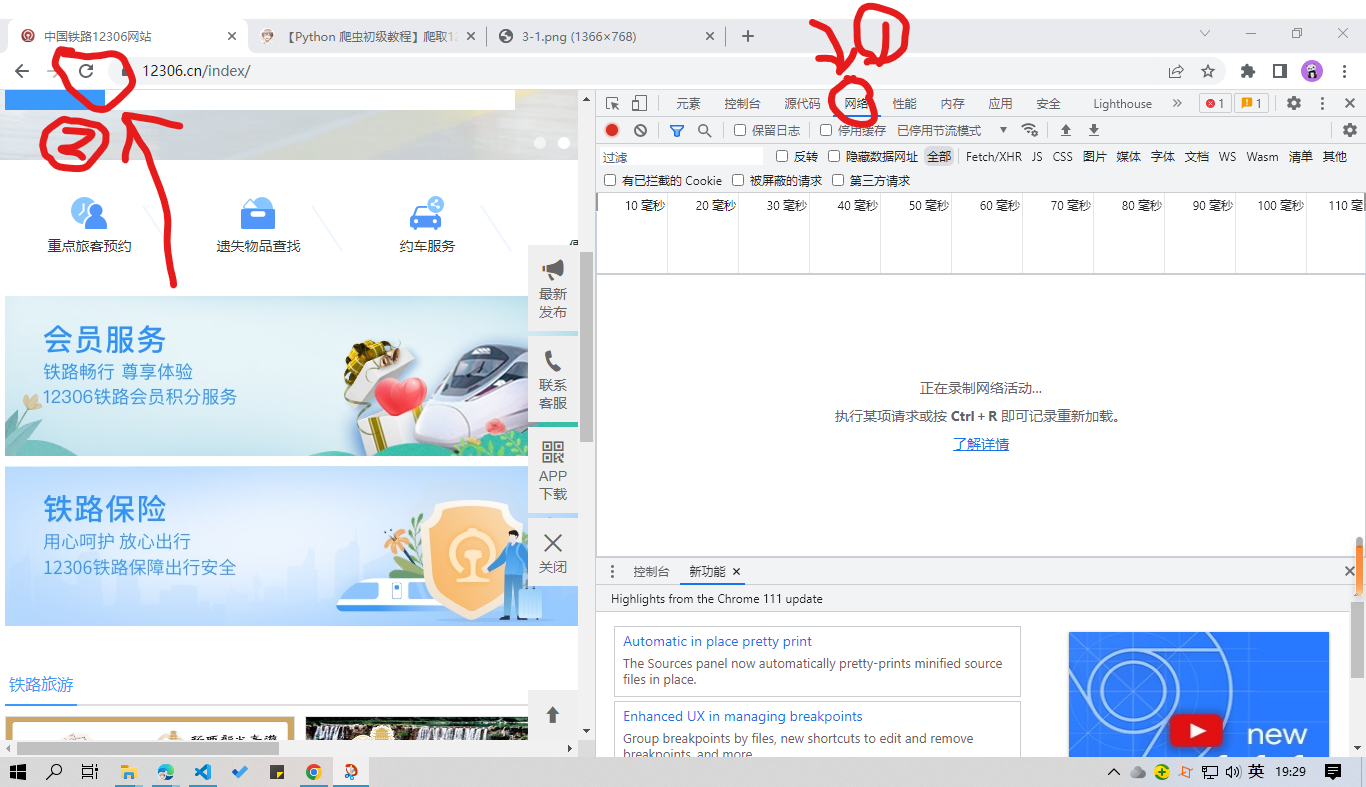
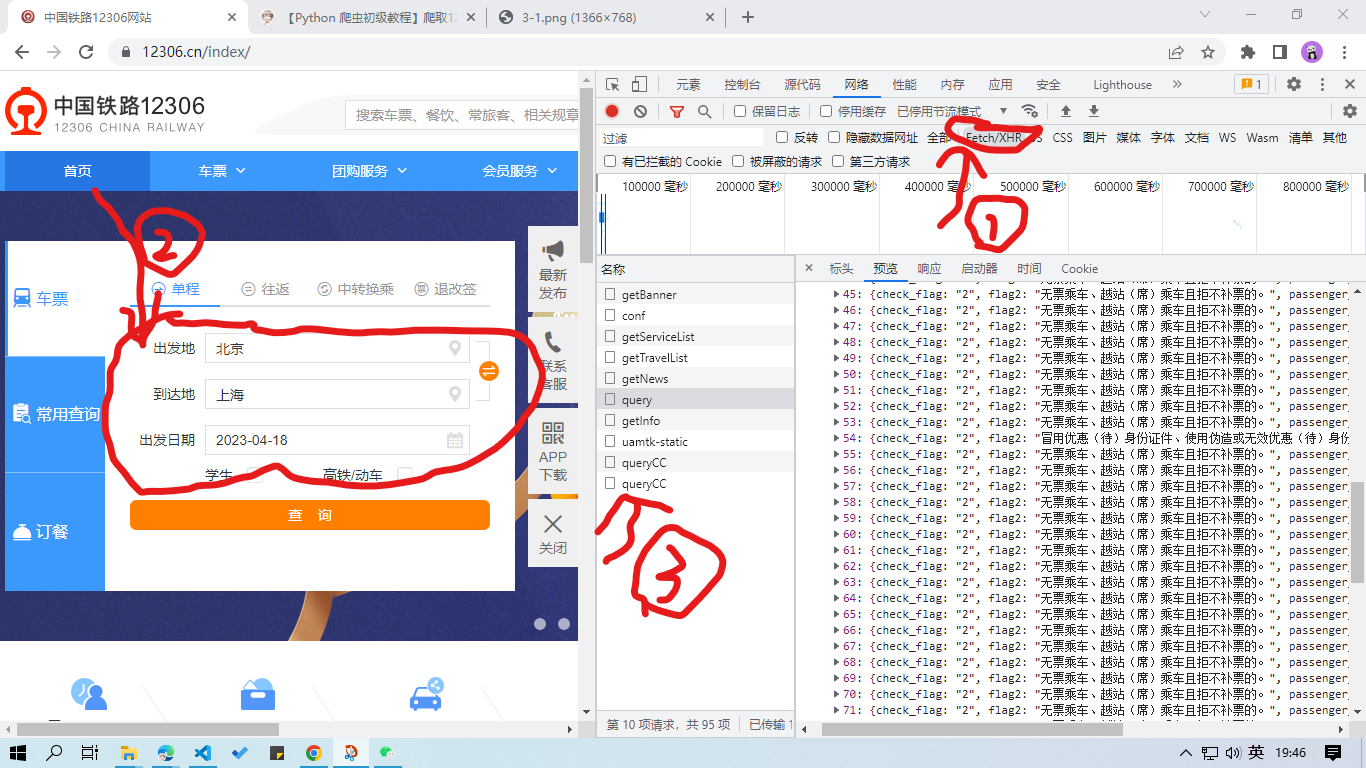
依图,点击 “Fetch/XHR” ,浏览资源列表,发现并无相关列车时刻信息。尝试随意填入出发地、到达地、出发日期,点击 “查询”,你又会看到许多资源文件。
你可以在点击 “查询” 前之点击图示按钮清除先前已加载的资源文件:
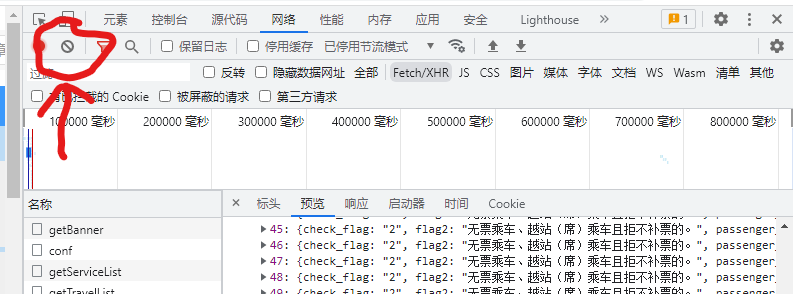
(哦~ 点击 “查询” 后会跳转至新标签页,上步无任何意义,在新标签页重新按 F12 进入 DevTools,刷新)
非常幸运,筛选出的这一个资源,正是我们想要的!
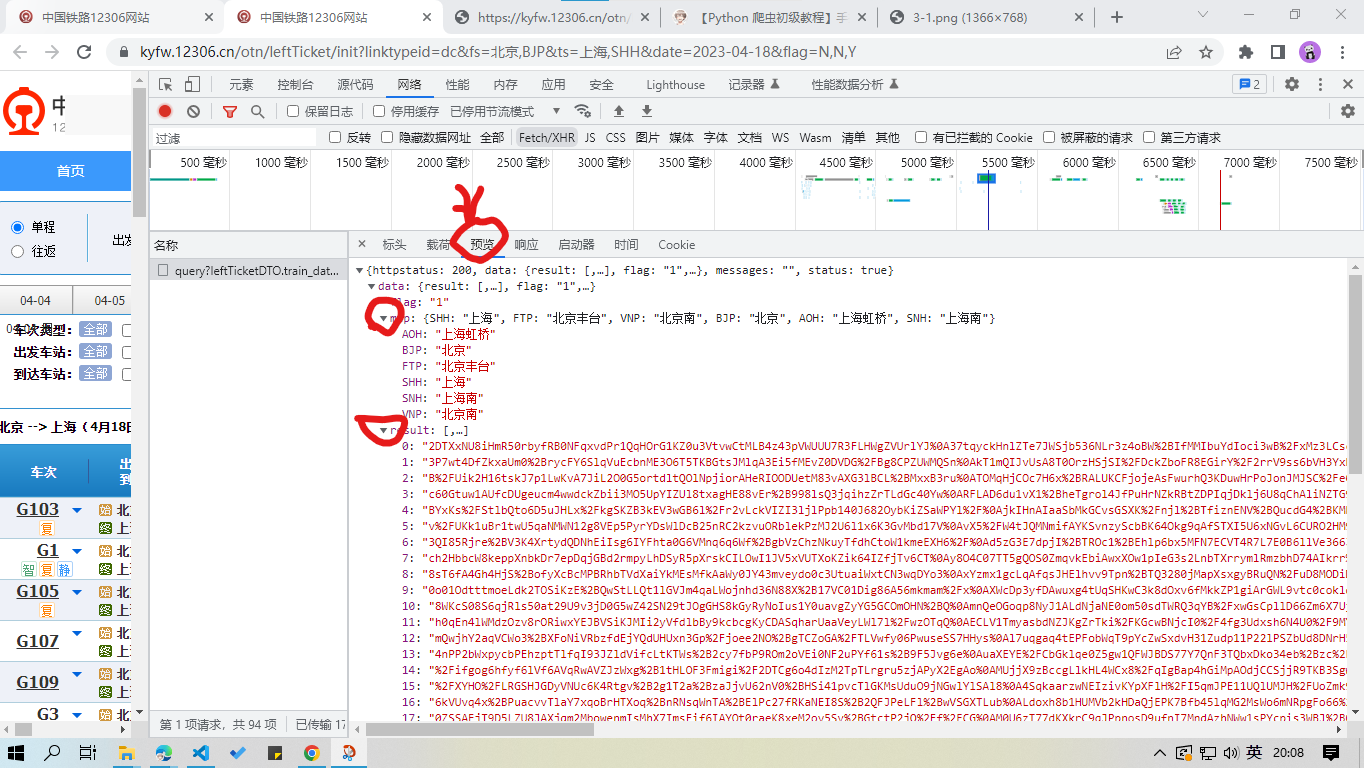
显然,返回的资源中 “map” 和 “result” 参数非常关键。”map” 参数反映了出发地和到达地所有车站的英文代码,”result” 参数反映了车次信息(信息还比较混乱,编写代码时再进行数据处理)。
对资源请求网址进行梳理。以 https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2023-06-18&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT 为例。"train_date=" 后为出发日期,"leftTicketDTO.from_station=" 后为出发地(站点或地区的英文代码均可),"leftTicketDTO.to_station=" 后为到达地(站点或地区的英文代码均可),"purpose_codes=" 后推测为车票类型,"ADULT" 表示成人票。
那么车站代码在何处?
重新返回 DevTools ,”Fetch/XHR” 文件类型并无车站代码的数据,只好点击 “全部” ,按照文件名和内容进行检索。发现一个名为 “station_name.js” 的文件中含有大量有关信息,记下资源数据网址 https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9255。
代码部分
处理数据
根据上面的分析,先处理车站代码信息。这时候需要找规律和熟悉使用 re 正则表达式。创建 tickets.py,定义主函数 main ,传入始发地、到达地、日期和票种。代码见下:
1
2
3
4
5
6
7
8
| def main(_from, _to, _date, _purpose_codes='ADULT'):
station_name_js_url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js'
response = get(station_name_js_url, headers=headers1)
stations = dict(findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)', response.text))
|
stations 为字典类型,便于之后的数据查找。
获取资源请求网址,并返回数据:
1
2
3
4
5
6
7
|
_from = stations[_from]
_to = stations[_to]
queryz_url = f'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={_date}&leftTicketDTO.from_station={_from}&leftTicketDTO.to_station={_to}&purpose_codes={_purpose_codes}'
response = get(queryz_url, headers=headers2)
queryz = loads(response.text)
|
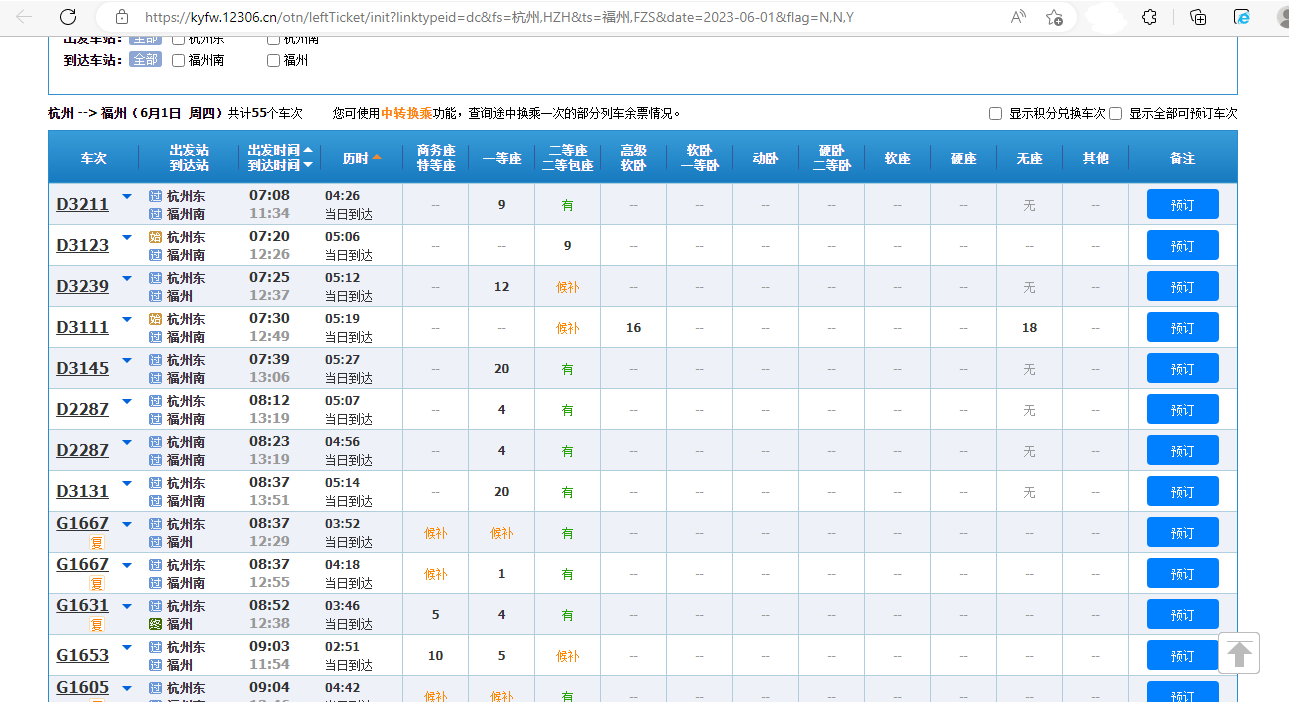
这时候 print(queryz) 会得到下图数据:

易发现,queryz 中同一车次多组数据用 ‘|’ 隔开,多车次信息位于 result 列表的个字符串中。
对于这些没有特征的混乱字符串,这时候只能去原网页比对数据(如图5),观察各等座的特殊值对应的数据位置,再进行 for 循环遍历所有字符串。必要时改变始发地、到达地和日期判断 queryz 中各位置上的有用信息。这步需要很强的数据处理能力。
具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| return_result = []
map_dict = queryz['data']['map']
trains_result = queryz['data']['result']
for i in trains_result:
d = i.split('|')
'''https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs={},{}&ts={},{}&date={}&flag=N,N,Y
缺少 软座 、 其他 的车票信息
车次 出发站 到达站 出发时间 到达时间 历时 商务座/特等座 一等座 二等座/二等包座 高级软卧 软卧一等卧 动卧
d[3] d[6] d[7] d[8] d[9] d[10] d[32] d[31] d[30] d[21] d[23] d[33]
硬卧二等卧 软座 硬座 无座 其它
d[28] x d[29] d[26] x
'''
return_result.append([[d[3], Fore.RED + map_dict[d[6]] + Style.RESET_ALL, Fore.RED + d[8] + Style.RESET_ALL,
pass_time(d[10]), none_str(d[32]), none_str(d[31]), none_str(d[30]), none_str(d[21]),
none_str(d[23]), none_str(d[33]), none_str(d[28]), none_str(d[29]), none_str(d[26])],
['', Fore.GREEN + map_dict[d[7]] + Style.RESET_ALL, Fore.GREEN + d[9] + Style.RESET_ALL,
'', '', '', '', '', '', '', '', '', '']])
return return_result
|
在处理数据时,发现解析后的数据与需打印数据不一致,需要作出处理。提前定义函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def none_str(string):
if string == '':
return '-'
elif string is None:
return '-'
else:
return string
def pass_time(string: str):
if len(string) == 5:
string = string.replace(':', '小时') + '分'
return string
else:
return None
|
返回 return_result 值时顺便加上 colorama 中的字体颜色模块。
漂亮的打印信息
这步主要考察 prettytable 库的使用,编写过程不赘述,附上代码。
新建 prettyprint.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import tickets
from prettytable import PrettyTable
def print_table(_from, _to, _date, _purpose_codes='ADULT'):
x = PrettyTable()
x.field_names = ['车次', '站点', '时间', '历时', '商务座/特等座', '一等座', '二等座/二等包座', '高级软卧',
'软卧一等卧',
'动卧', '硬卧二等卧', '硬座', '无座']
lists = tickets.main(_from, _to, _date, _purpose_codes='ADULT')
for i in lists:
for s in i:
x.add_row(s)
print(x)
if __name__ == '__main__':
from_ = '北京'
to = '杭州'
date = '2023-06-01'
purpose_codes = 'ADULT'
print_table(from_, to, date, purpose_codes)
|
打印出来的就是带有颜色的表格啦!
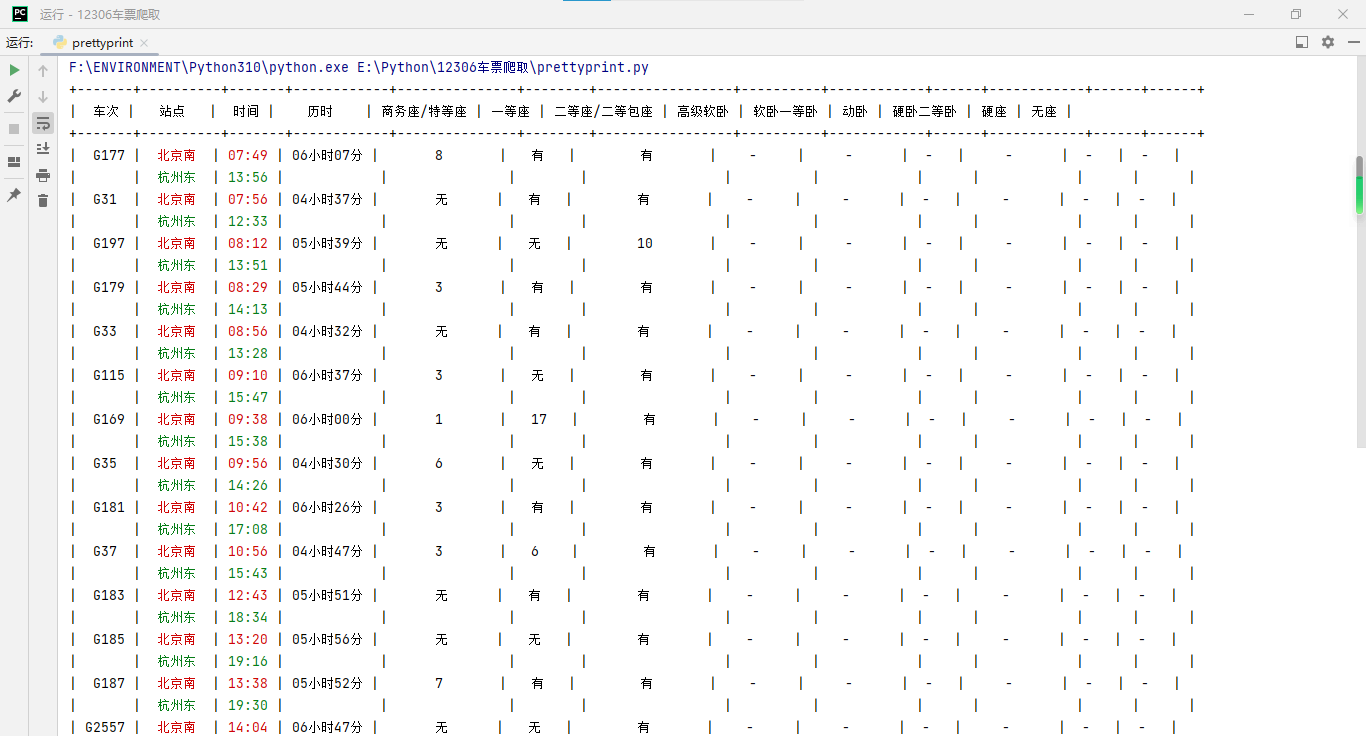
(PyCharm 的文字排版出了点问题,应该是因为空格、数字、汉字与标点所占的字符大小不同)
文件资源分享
Python 库需自行下载,zip 文件中含文中提及的两个 Python 文件。
点击下载
后记
像 12306 等诸如此类的网站信息时效性较短,接口数据变动频繁。若运行 py 文件时发现程序无法运行,请及时在评论区反映,风将会在尽可能短的时间内处理!

